ReplacingMergeTree
While transactional databases are optimized for transactional update and delete workloads, OLAP databases offer reduced guarantees for such operations. Instead, they optimize for immutable data inserted in batches for the benefit of significantly faster analytical queries. While ClickHouse offers update operations through mutations, as well as a lightweight means of deleting rows, its column-orientated structure means these operations should be scheduled with care, as described above. These operations are handled asynchronously, processed with a single thread, and require (in the case of updates) data to be rewritten on disk. They should thus not be used for high numbers of small changes. In order to process a stream of update and delete rows while avoiding the above usage patterns, we can use the ClickHouse table engine ReplacingMergeTree.
Automatic upserts of inserted rows
The ReplacingMergeTree table engine allows update operations to be applied to rows, without needing to use inefficient ALTER or DELETE statements, by offering the ability for users to insert multiple copies of the same row and denote one as the latest version. A background process, in turn, asynchronously removes older versions of the same row, efficiently imitating an update operation through the use of immutable inserts.
This relies on the ability of the table engine to identify duplicate rows. This is achieved using the ORDER BY clause to determine uniqueness, i.e., if two rows have the same values for the columns specified in the ORDER BY, they are considered duplicates. A version column, specified when defining the table, allows the latest version of a row to be retained when two rows are identified as duplicates i.e. the row with the highest version value is kept.
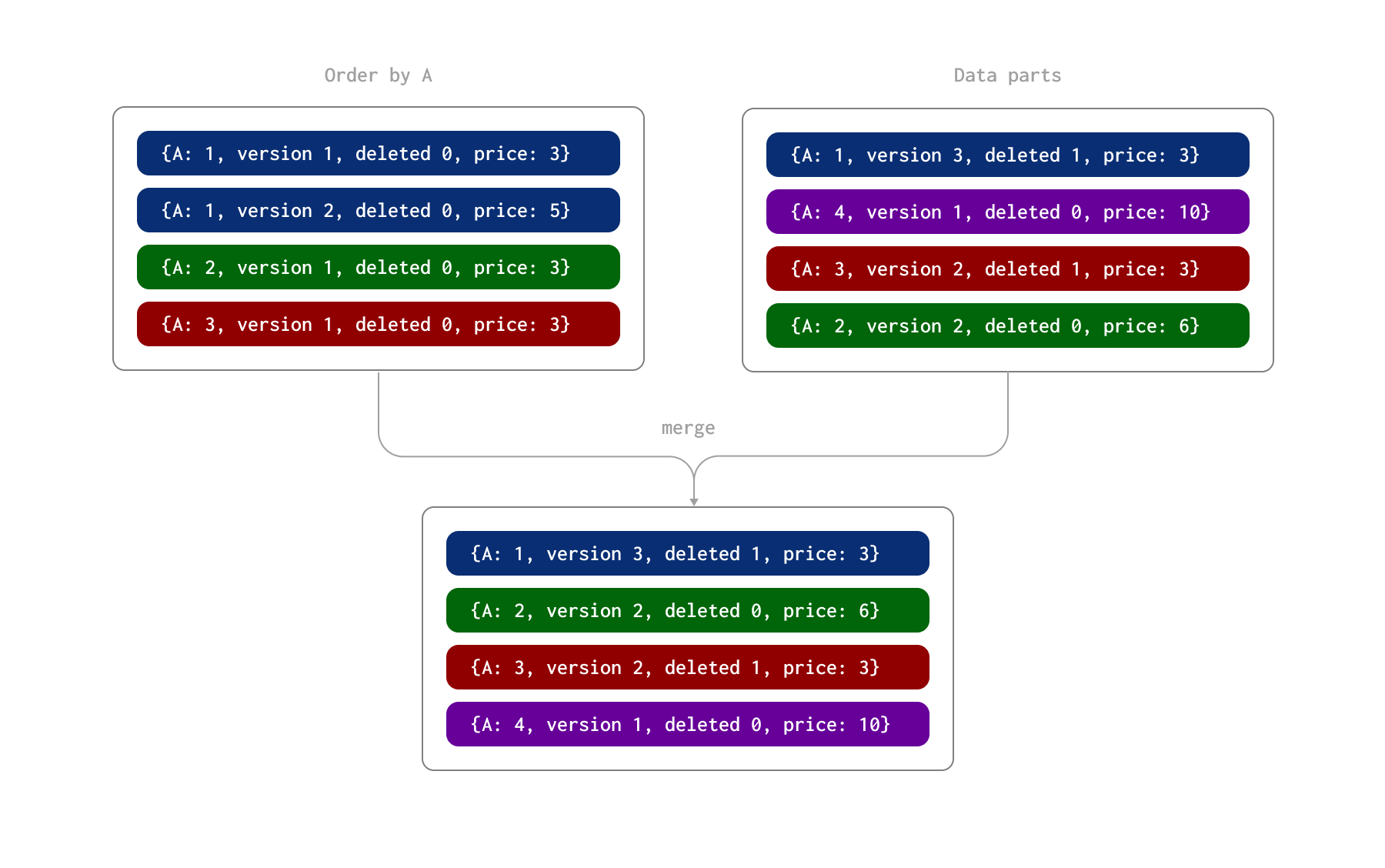
We illustrate this process in the example below. Here, the rows are uniquely identified by the A column (the ORDER BY for the table). We assume these rows have been inserted as two batches, resulting in the formation of two data parts on disk. Later, during an asynchronous background process, these parts are merged together.
ReplacingMergeTree additionally allows a deleted column to be specified. This can contain either 0 or 1, where a value of 1 indicates that the row (and its duplicates) has been deleted and zero is used otherwise. Note: Deleted rows will not be removed at merge time.
During this process, the following occurs during part merging:
- The row identified by the value 1 for column A has both an update row with version 2 and a delete row with version 3 (and a deleted column value of 1). The latest row, marked as deleted, is therefore retained.
- The row identified by the value 2 for column A has two update rows. The latter row is retained with a value of 6 for the price column.
- The row identified by the value 3 for column A has a row with version 1 and a delete row with version 2. This delete row is retained.
As a result of this merge process, we have four rows representing the final state:
Note that deleted rows are never removed. They can be forcibly deleted with an OPTIMIZE table FINAL CLEANUP. This requires the experimental setting allow_experimental_replacing_merge_with_cleanup=1. This should only be issued under the following conditions:
- You can be sure that no rows with old versions (for those that are being deleted with the cleanup) will be inserted after the operation is issued. If these are inserted, they will be incorrectly retained, as the deleted rows will no longer be present.
- Ensure all replicas are in sync prior to issuing the cleanup. This can be achieved with the command:
SYSTEM SYNC REPLICA table
We recommend pausing inserts once (1) is guaranteed and until this command and the subsequent cleanup are complete.
Handling deletes with the ReplacingMergeTree is only recommended for tables with a low to moderate number of deletes (less than 10%) unless periods can be scheduled for cleanup with the above conditions.
Tip: Users may also be able to issue
OPTIMIZE FINAL CLEANUPagainst selective partitions no longer subject to changes.
Choosing a primary/deduplication key
Above, we highlighted an important additional constraint that must also be satisfied in the case of the ReplacingMergeTree: the values of columns of the ORDER BY uniquely identify a row across changes. If migrating from a transactional database like Postgres, the original Postgres primary key should thus be included in the Clickhouse ORDER BY clause.
Users of ClickHouse will be familiar with choosing the columns in their tables ORDER BY clause to optimize for query performance. Generally, these columns should be selected based on your frequent queries and listed in order of increasing cardinality. Importantly, the ReplacingMergeTree imposes an additional constraint - these columns must be immutable, i.e., if replicating from Postgres, only add columns to this clause if they do not change in the underlying Postgres data. While other columns can change, these are required to be consistent for unique row identification.
For analytical workloads, the Postgres primary key is generally of little use as users will rarely perform point row lookups. Given we recommend that columns be ordered in order of increasing cardinality, as well as the fact that matches on columns listed earlier in the ORDER BY will usually be faster, the Postgres primary key should be appended to the end of the ORDER BY (unless it has analytical value). In the case that multiple columns form a primary key in Postgres, they should be appended to the ORDER BY, respecting cardinality and the likelihood of query value. Users may also wish to generate a unique primary key using a concatenation of values via a MATERIALIZED column.
Consider the posts table from the Stack Overflow dataset.
CREATE TABLE stackoverflow.posts_updateable
(
`Version` UInt32,
`Deleted` UInt8,
`Id` Int32 CODEC(Delta(4), ZSTD(1)),
`PostTypeId` Enum8('Question' = 1, 'Answer' = 2, 'Wiki' = 3, 'TagWikiExcerpt' = 4, 'TagWiki' = 5, 'ModeratorNomination' = 6, 'WikiPlaceholder' = 7, 'PrivilegeWiki' = 8),
`AcceptedAnswerId` UInt32,
`CreationDate` DateTime64(3, 'UTC'),
`Score` Int32,
`ViewCount` UInt32 CODEC(Delta(4), ZSTD(1)),
`Body` String,
`OwnerUserId` Int32,
`OwnerDisplayName` String,
`LastEditorUserId` Int32,
`LastEditorDisplayName` String,
`LastEditDate` DateTime64(3, 'UTC') CODEC(Delta(8), ZSTD(1)),
`LastActivityDate` DateTime64(3, 'UTC'),
`Title` String,
`Tags` String,
`AnswerCount` UInt16 CODEC(Delta(2), ZSTD(1)),
`CommentCount` UInt8,
`FavoriteCount` UInt8,
`ContentLicense` LowCardinality(String),
`ParentId` String,
`CommunityOwnedDate` DateTime64(3, 'UTC'),
`ClosedDate` DateTime64(3, 'UTC')
)
ENGINE = ReplacingMergeTree(Version, Deleted)
PARTITION BY toYear(CreationDate)
ORDER BY (PostTypeId, toDate(CreationDate), CreationDate, Id)
We use an ORDER BY key of (PostTypeId, toDate(CreationDate), CreationDate, Id). The Id column, unique for each post, ensures rows can be deduplicated. A Version and Deleted column are added to the schema as required.
Querying ReplacingMergeTree
At merge time, the ReplacingMergeTree identifies duplicate rows, using the values of the ORDER BY columns as a unique identifier, and either retains only the highest version or removes all duplicates if the latest version indicates a delete. This, however, offers eventual correctness only - it does not guarantee rows will be deduplicated, and you should not rely on it. Queries can, therefore, produce incorrect answers due to update and delete rows being considered in queries.
To obtain correct answers, users will need to complement background merges with query time deduplication and deletion removal. This can be achieved using the FINAL operator.
Consider the posts table above. We can use the normal method of loading this dataset but specify a deleted and version column in addition to values 0. For example purposes, we load 10000 rows only.
INSERT INTO stackoverflow.posts_updateable SELECT 0 AS Version, 0 AS Deleted, *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/*.parquet') WHERE AnswerCount > 0 LIMIT 10000
0 rows in set. Elapsed: 1.980 sec. Processed 8.19 thousand rows, 3.52 MB (4.14 thousand rows/s., 1.78 MB/s.)
Let's confirm the number of rows:
SELECT count() FROM stackoverflow.posts_updateable
┌─count()─┐
│ 10000 │
└─────────┘
1 row in set. Elapsed: 0.002 sec.
We now update our post-answer statistics. Rather than updating these values, we insert new copies of 5000 rows and add one to their version number (this means 150 rows will exist in the table). We can simulate this with a simple INSERT INTO SELECT:
INSERT INTO posts_updateable SELECT
Version + 1 AS Version,
Deleted,
Id,
PostTypeId,
AcceptedAnswerId,
CreationDate,
Score,
ViewCount,
Body,
OwnerUserId,
OwnerDisplayName,
LastEditorUserId,
LastEditorDisplayName,
LastEditDate,
LastActivityDate,
Title,
Tags,
AnswerCount,
CommentCount,
FavoriteCount,
ContentLicense,
ParentId,
CommunityOwnedDate,
ClosedDate
FROM posts_updateable --select 100 random rows
WHERE (Id % toInt32(floor(randUniform(1, 11)))) = 0
LIMIT 5000
0 rows in set. Elapsed: 4.056 sec. Processed 1.42 million rows, 2.20 GB (349.63 thousand rows/s., 543.39 MB/s.)
In addition, we delete 1000 random posts by reinserting the rows but with a deleted column value of 1. Again, simulating this can be simulated with a simple INSERT INTO SELECT.
INSERT INTO posts_updateable SELECT
Version + 1 AS Version,
1 AS Deleted,
Id,
PostTypeId,
AcceptedAnswerId,
CreationDate,
Score,
ViewCount,
Body,
OwnerUserId,
OwnerDisplayName,
LastEditorUserId,
LastEditorDisplayName,
LastEditDate,
LastActivityDate,
Title,
Tags,
AnswerCount + 1 AS AnswerCount,
CommentCount,
FavoriteCount,
ContentLicense,
ParentId,
CommunityOwnedDate,
ClosedDate
FROM posts_updateable --select 100 random rows
WHERE (Id % toInt32(floor(randUniform(1, 11)))) = 0 AND AnswerCount > 0
LIMIT 1000
0 rows in set. Elapsed: 0.166 sec. Processed 135.53 thousand rows, 212.65 MB (816.30 thousand rows/s., 1.28 GB/s.)
The result of the above operations will be 16,000 rows i.e. 10,000 + 5000 + 1000. The correct total here is, reality we should have only 1000 rows less than our original total i.e. 10,000 - 1000 = 9000.
SELECT count()
FROM posts_updateable
┌─count()─┐
│ 10000 │
└─────────┘
1 row in set. Elapsed: 0.002 sec.
Your results will vary here depending on the merges that have occurred. We can see the total here is different as we have duplicate rows. Applying FINAL to the table delivers the correct result.
SELECT count()
FROM posts_updateable
FINAL
┌─count()─┐
│ 9000 │
└─────────┘
1 row in set. Elapsed: 0.006 sec. Processed 11.81 thousand rows, 212.54 KB (2.14 million rows/s., 38.61 MB/s.)
Peak memory usage: 8.14 MiB.
FINAL performance
The FINAL operator will have a performance overhead on queries despite ongoing improvements. This will be most appreciable when queries are not filtering on primary key columns, causing more data to be read and increasing the deduplication overhead. If users filter on key columns using a WHERE condition, the data loaded and passed for deduplication will be reduced.
If the WHERE condition does not use a key column, ClickHouse does not currently utilize the PREWHERE optimization when using FINAL. This optimization aims to reduce the rows read for non-filtered columns. Examples of emulating this PREWHERE and thus potentially improving performance can be found here.
Exploiting partitions with ReplacingMergeTree
Merging of data in ClickHouse occurs at a partition level. When using ReplacingMergeTree, we recommend users partition their table according to best practices, provided users can ensure this partitioning key does not change for a row. This will ensure updates pertaining to the same row will be sent to the same ClickHouse partition. You may reuse the same partition key as Postgres provided you adhere to the best practices outlined here.
Assuming this is the case, users can use the setting do_not_merge_across_partitions_select_final=1 to improve FINAL query performance. This setting causes partitions to be merged and processed independently when using FINAL.
Consider the following posts table, where we use no partitioning:
CREATE TABLE stackoverflow.posts_no_part
(
`Version` UInt32,
`Deleted` UInt8,
`Id` Int32 CODEC(Delta(4), ZSTD(1)),
…
)
ENGINE = ReplacingMergeTree
ORDER BY (PostTypeId, toDate(CreationDate), CreationDate, Id)
INSERT INTO stackoverflow.posts_no_part SELECT 0 AS Version, 0 AS Deleted, *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/*.parquet')
0 rows in set. Elapsed: 182.895 sec. Processed 59.82 million rows, 38.07 GB (327.07 thousand rows/s., 208.17 MB/s.)
To ensure FINAL is required to do some work, we update 1m rows - incrementing their AnswerCount by inserting duplicate rows.
INSERT INTO posts_no_part SELECT Version + 1 AS Version, Deleted, Id, PostTypeId, AcceptedAnswerId, CreationDate, Score, ViewCount, Body, OwnerUserId, OwnerDisplayName, LastEditorUserId, LastEditorDisplayName, LastEditDate, LastActivityDate, Title, Tags, AnswerCount + 1 AS AnswerCount, CommentCount, FavoriteCount, ContentLicense, ParentId, CommunityOwnedDate, ClosedDate
FROM posts_no_part
LIMIT 1000000
Computing the sum of answers per year with FINAL:
SELECT toYear(CreationDate) AS year, sum(AnswerCount) AS total_answers
FROM posts_no_part
FINAL
GROUP BY year
ORDER BY year ASC
┌─year─┬─total_answers─┐
│ 2008 │ 371480 │
…
│ 2024 │ 127765 │
└──────┴───────────────┘
17 rows in set. Elapsed: 2.338 sec. Processed 122.94 million rows, 1.84 GB (52.57 million rows/s., 788.58 MB/s.)
Peak memory usage: 2.09 GiB.
Repeating these same steps for a table partitioning by year, and repeating the above query with do_not_merge_across_partitions_select_final=1.
CREATE TABLE stackoverflow.posts_with_part
(
`Version` UInt32,
`Deleted` UInt8,
`Id` Int32 CODEC(Delta(4), ZSTD(1)),
...
)
ENGINE = ReplacingMergeTree
PARTITION BY toYear(CreationDate)
ORDER BY (PostTypeId, toDate(CreationDate), CreationDate, Id)
// populate & update omitted
SELECT toYear(CreationDate) AS year, sum(AnswerCount) AS total_answers
FROM posts_with_part
FINAL
GROUP BY year
ORDER BY year ASC
┌─year─┬─total_answers─┐
│ 2008 │ 387832 │
│ 2009 │ 1165506 │
│ 2010 │ 1755437 │
...
│ 2023 │ 787032 │
│ 2024 │ 127765 │
└──────┴───────────────┘
17 rows in set. Elapsed: 0.994 sec. Processed 64.65 million rows, 983.64 MB (65.02 million rows/s., 989.23 MB/s.)
As shown, partitioning has significantly improved query performance in this case by allowing the deduplication process to occur at a partition level in parallel.
Merge Behavior Considerations
ClickHouse’s merge selection mechanism goes beyond simple merging of parts. Below, we examine this behavior in the context of ReplacingMergeTree, including configuration options for enabling more aggressive merging of older data and considerations for larger parts.
Merge Selection Logic
While merging aims to minimize the number of parts, it also balances this goal against the cost of write amplification. Consequently, some ranges of parts are excluded from merging if they would lead to excessive write amplification, based on internal calculations. This behavior helps prevent unnecessary resource usage and extends the lifespan of storage components.
Merging Behavior on Large Parts
The ReplacingMergeTree engine in ClickHouse is optimized for managing duplicate rows by merging data parts, keeping only the latest version of each row based on a specified unique key. However, when a merged part reaches the max_bytes_to_merge_at_max_space_in_pool threshold, it will no longer be selected for further merging, even if min_age_to_force_merge_seconds is set. As a result, automatic merges can no longer be relied upon to remove duplicates that may accumulate with ongoing data insertion.
To address this, users can invoke OPTIMIZE FINAL to manually merge parts and remove duplicates. Unlike automatic merges, OPTIMIZE FINAL bypasses the max_bytes_to_merge_at_max_space_in_pool threshold, merging parts based solely on available resources, particularly disk space, until a single part remains in each partition. However, this approach can be memory-intensive on large tables and may require repeated execution as new data is added.
For a more sustainable solution that maintains performance, partitioning the table is recommended. This can help prevent data parts from reaching the maximum merge size and reduces the need for ongoing manual optimizations.
Partitioning and Merging Across Partitions
As discussed in Exploiting Partitions with ReplacingMergeTree, we recommend partitioning tables as a best practice. Partitioning isolates data for more efficient merges and avoids merging across partitions, particularly during query execution. This behavior is enhanced in versions from 23.12 onward: if the partition key is a prefix of the sorting key, merging across partitions is not performed at query time, leading to faster query performance.
Tuning Merges for Better Query Performance
By default, min_age_to_force_merge_seconds and min_age_to_force_merge_on_partition_only are set to 0 and false, respectively, disabling these features. In this configuration, ClickHouse will apply standard merging behavior without forcing merges based on partition age.
If a value for min_age_to_force_merge_seconds is specified, ClickHouse will ignore normal merging heuristics for parts older than the specified period. While this is generally only effective if the goal is to minimize the total number of parts, it can improve query performance in ReplacingMergeTree by reducing the number of parts needing merging at query time.
This behavior can be further tuned by setting min_age_to_force_merge_on_partition_only=true, requiring all parts in the partition to be older than min_age_to_force_merge_seconds for aggressive merging. This configuration allows older partitions to merge down to a single part over time, which consolidates data and maintains query performance.
Recommended Settings
Tuning merge behavior is an advanced operation. We recommend consulting with ClickHouse support before enabling these settings in production workloads.
In most cases, setting min_age_to_force_merge_seconds to a low value—significantly less than the partition period—is preferred. This minimizes the number of parts and prevents unnecessary merging at query time with the FINAL operator.
For example, consider a monthly partition that has already been merged into a single part. If a small, stray insert creates a new part within this partition, query performance can suffer because ClickHouse must read multiple parts until the merge completes. Setting min_age_to_force_merge_seconds can ensure these parts are merged aggressively, preventing a degradation in query performance.