Loading data from PostgreSQL to ClickHouse
This is Part 1 of a guide on migrating from PostgreSQL to ClickHouse. This content can be considered introductory, with the aim of helping users deploy an initial functional system that adheres to ClickHouse best practices. It avoids complex topics and will not result in a fully optimized schema; rather, it provides a solid foundation for users to build a production system and base their learning.
Dataset
As an example dataset to show a typical migration from Postgres to ClickHouse, we use the Stack Overflow dataset documented here. This contains every post, vote, user, comment, and badge that has occurred on Stack Overflow from 2008 to Apr 2024. The PostgreSQL schema for this data is shown below:
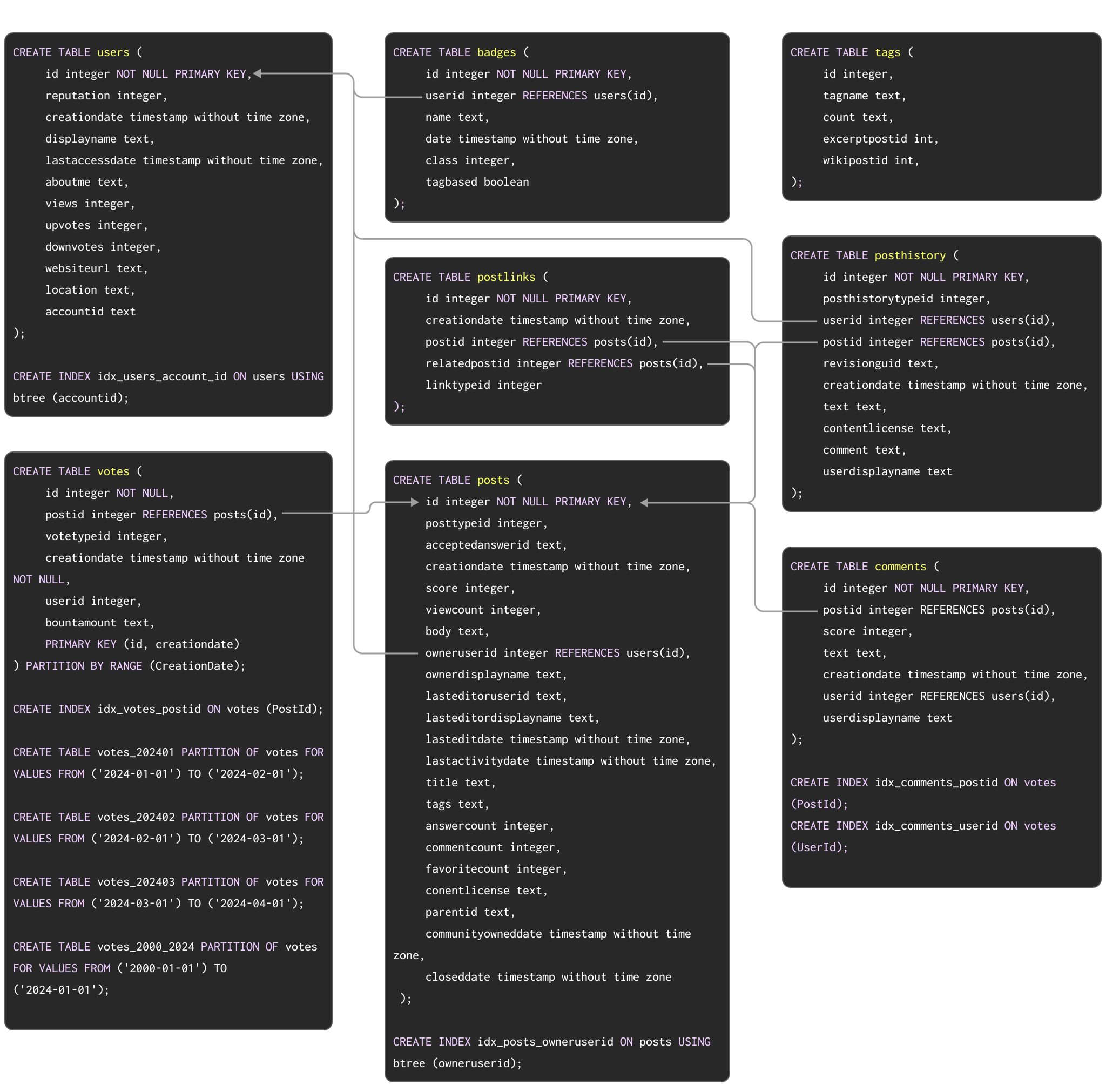
DDL commands to create the tables in PostgreSQL are available here.
This schema, while not necessarily the most optimal, exploits a number of popular PostgreSQL features, including primary keys, foreign keys, partitioning, and indexes.
We will migrate each of these concepts to their ClickHouse equivalents.
For those users who wish to populate this dataset into a PostgreSQL instance to test migration steps, we have provided the data in pg_dump format for download with the DDL, and subsequent data load commands are shown below:
# users
wget https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/pdump/2024/users.sql.gz
gzip -d users.sql.gz
psql < users.sql
# posts
wget https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/pdump/2024/posts.sql.gz
gzip -d posts.sql.gz
psql < posts.sql
# posthistory
wget https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/pdump/2024/posthistory.sql.gz
gzip -d posthistory.sql.gz
psql < posthistory.sql
# comments
wget https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/pdump/2024/comments.sql.gz
gzip -d comments.sql.gz
psql < comments.sql
# votes
wget https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/pdump/2024/votes.sql.gz
gzip -d votes.sql.gz
psql < votes.sql
# badges
wget https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/pdump/2024/badges.sql.gz
gzip -d badges.sql.gz
psql < badges.sql
# postlinks
wget https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/pdump/2024/postlinks.sql.gz
gzip -d postlinks.sql.gz
psql < postlinks.sql
While small for ClickHouse, this dataset is substantial for Postgres. The above represents a subset covering the first three months of 2024.
While our example results use the full dataset to show performance differences between Postgres and Clickhouse, all steps documented below are functionally identical with the smaller subset. Users wanting to load the full dataset into Postgres see here. Due to the foreign constraints imposed by the above schema, the full dataset for PostgreSQL only contains rows that satisfy referential integrity. A Parquet version, with no such constraints, can be easily loaded directly into ClickHouse if needed.
Migrating data
Migrating data between ClickHouse and Postgres falls into two primary workload types:
- Initial bulk load with periodic updates - An initial dataset must be migrated along with periodic updates at set intervals e.g. daily. Updates here are handled by resending rows that have changed - identified by either a column that can be used for comparisons (e.g., a date) or the XMIN value. Deletes are handled with a complete periodic reload of the dataset.
- Real time replication or CDC - An initial dataset must be migrated. Changes to this dataset must be reflected in ClickHouse in near-real time with only a delay of several seconds acceptable. This is effectively a Change Data Capture (CDC) process where tables in Postgres must be synchronized with ClickHouse i.e. Inserts, updates and deletes in the Postgres table must be applied to an equivalent table in ClickHouse.
Initial bulk load with periodic updates
This workload represents the simpler of the above workloads since changes can be periodically applied. An initial bulk load of the dataset can be achieved via:
- Table functions - Using the Postgres table function in ClickHouse to
SELECTdata from Postgres andINSERTit into a ClickHouse table. Relevant to bulk loads up to datasets of several hundred GB. - Exports - Exporting to intermediary formats such as CSV or SQL script file. These files can then be loaded into ClickHouse from either the client via the
INSERT FROM INFILEclause or using object storage and their associated functions i.e. s3, gcs.
Incremental loads can, in turn, be scheduled. If the Postgres table only receives inserts and an incrementing id or timestamp exists, users can use the above table function approach to load increments, i.e. a WHERE clause can be applied to the SELECT. This approach may also be used to support updates if these are guaranteed to update the same column. Supporting deletes will, however, require a complete reload, which may be difficult to achieve as the table grows.
We demonstrate an initial load and incremental load using the CreationDate (we assume this gets updated if rows are updated)..
-- initial load
INSERT INTO stackoverflow.posts SELECT * FROM postgresql('<host>', 'postgres', 'posts', 'postgres', '<password')
INSERT INTO stackoverflow.posts SELECT * FROM postgresql('<host>', 'postgres', 'posts', 'postgres', '<password') WHERE CreationDate > ( SELECT (max(CreationDate) FROM stackoverflow.posts)
ClickHouse will push down simple
WHEREclauses such as =, !=, >, >=, <, <=, and IN to the PostgreSQL server. Incremental loads can thus be made more efficient by ensuring an index exists on columns used to identify the change set.
A possible method to detect UPDATE operations when using query replication is using the XMIN system column (transaction IDs) as a watermark - a change in this column is indicative of a change and therefore can be applied to the destination table. Users employing this approach should be aware that XMIN values can wrap around and comparisons require a full table scan, making tracking changes more complex. For further details on this approach, see "Change Data Capture (CDC)".
Real time replication or CDC
Change Data Capture (CDC) is the process by which tables are kept in sync between two databases. This is significantly more complex if updates and deletes are to be handled in near real-time. Several solutions currently exist:
PeerDB by ClickHouse - PeerDB offers an open code specialist Postgres CDC solution users can run self-managed or through a SaaS solution, which has shown to perform well at scale with Postgres and ClickHouse. The solution focuses on low-level optimizations to achieve high-performance transfer data and reliability guarantees between Postgres and ClickHouse. It supports both online and offline loads.
InfoPeerDB is now available natively in ClickHouse Cloud - Blazing-fast Postgres to ClickHouse CDC with our new ClickPipe connector - now in Private Preview. Please sign up here
Build your own - This can be achieved with Debezium + Kafka - Debezium offers the ability to capture all changes on a Postgres table, forwarding these as events to a Kafka queue. These events can then be consumed by either the ClickHouse Kafka connector or Clickpipes in ClickHouse Cloud, for insertion into ClickHouse. This represents Change Data Capture (CDC) as Debezium will not only perform an initial copy of the tables but also ensure all subsequent updates, deletes, and inserts are detected on Postgres, resulting in the downstream events. This requires careful configuration of both Postgres, Debezium, and ClickHouse. Examples can be found here.
For the examples in this guide, we assume an initial bulk load only, focusing on data exploration and easy iteration toward production schemas usable for other approaches.